Vector stores
Vector stores, essentially databases or data structures, are specifically engineered to manage high-dimensional vectors. They typically support operations that find vectors most similar to a specific vector. Such operations are particularly beneficial when dealing with embeddings, which are vectors that encapsulate the semantic essence of words. To put it succinctly, vector stores are highly valuable when the goal is to identify texts semantically similar to a specified piece of text.
OpenAI Embeddings
Let's consider an example of generating embeddings using one of OpenAI's models:
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
output = embeddings.embed_query("Giraffes are tall")
print(output)
The result of this operation is a list of real numbers, exceeding 1000 elements. This multidimensional vector carries the semantic meaning of the sentence.
FAISS
FAISS (Facebook AI Similarity Search) is a library designed for efficient storage of vectors and performing operations, such as searching for vectors similar to a specified vector. When employed with embeddings, it can be utilised to locate texts semantically similar to a given text. LangChain offers a user-friendly interface for leveraging FAISS.
To install FAISS:
pip install faiss-cpu
Here is an example of how FAISS can be used with embeddings:
from langchain.schema import Document
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores.faiss import FAISS
data = [
"Dogs take pleasure in consuming bread",
"Dogs run fast",
"Humans don't like to eat dog food",
"Biscuits are the favourite food of canines",
"Dogs like to eat crisps",
"Humans like to eat hot dogs",
]
docs = [Document(page_content=s) for s in data]
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(docs, embeddings)
answers = vectorstore.similarity_search_with_score(
query="What do dogs like to eat?", k=6
)
for answer in answers:
sentence = answer[0].page_content
score = answer[1]
print(f"{sentence}, {score}")
Output:
Dogs like to eat crisps, 0.21053916215896606
Dogs take pleasure in consuming bread, 0.2522420287132263
Biscuits are the favourite food of canines, 0.2554807960987091
Humans like to eat hot dogs, 0.28732240200042725
Humans don't like to eat dog food, 0.31627824902534485
Dogs run fast, 0.34649500250816345
Several steps occur when the FAISS.from_documents function is called:
- The OpenAI model generates embeddings.
- These embeddings are stored in the FAISS vector store for semantic similarity searches.
- The original sentences are stored in an in-memory database so we can return the original text after performing a semantic similarity search.
Next, a search process initiates for the query What do dogs like to eat?. Behind the scenes, embeddings are generated for the query and used in the FAISS data store to find the vectors with the highest similarity. The process returns six results, each sorted by their semantic similarity to the query. An additional score parameter is returned, which is related to the distance between the query and each returned sentence. A higher value signifies less correlation between the query and the sentence.
Looking at the results, the sentence Dogs like to eat crisps is the most relevant to the query, as it has the lowest score. On the other hand, the sentence Dogs run fast has the highest score, making it the least relevant. Interestingly, the sentence Biscuits are the favourite food of canines is identified as fairly related to the query, despite not sharing any words with it. This implies that the semantic search process has accurately evaluated the relationship between these sentences.
Retrievers
A retriever is a component that returns data relevant to a given query, which can then be used by a large language model as context for answering the query. Typically, vector data stores serve as the source of context data.
Let's examine an example of how a vector store and a large language model can be used to answer queries:
from langchain.llms import OpenAI
from langchain.chains import RetrievalQA
from langchain.schema import Document
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores.faiss import FAISS
data = [
"Dogs take pleasure in consuming bread",
"Dogs run fast",
"Humans don't like to eat dog food",
"Biscuits are the favourite food of canines",
"Dogs like to eat crisps",
"Humans like to eat hot dogs",
]
docs = [Document(page_content=s) for s in data]
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(docs, embeddings)
llm = OpenAI(temperature=0)
qa = RetrievalQA.from_chain_type(
llm=llm, chain_type="stuff", retriever=vectorstore.as_retriever()
)
print(qa({"query": "What do dogs like to eat?"})["result"])
Output:
Dogs like to eat crisps, bread, and biscuits.
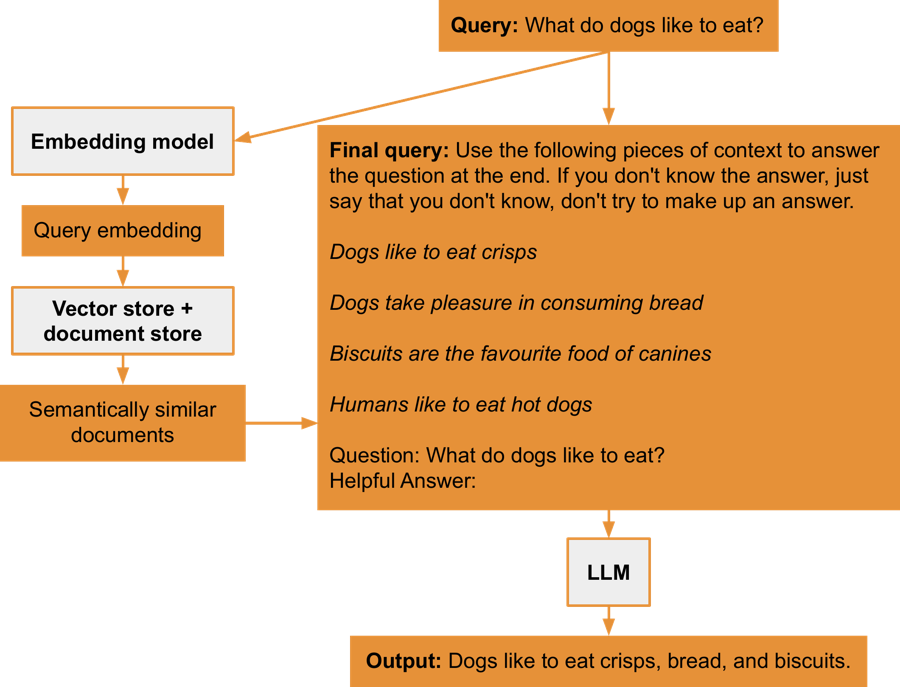
The vector store is populated with embeddings of several sentences from a previous example. RetrievalQA is a specialized chain that uses the vector store to obtain context data, which is then sent along with the query. This allows the large language model to use this context to formulate an answer. The retriever interface accesses the data in the vector store, usually returning data that is semantically similar to the query. An argument chain_type is provided, with its value being stuff from stuffing. Stuffing refers to the practice of fully appending all related documents returned by the vector store to the query sent to the large language model as context.
The answer to the question is Dogs like to eat crisps, bread, and biscuits.. This indicates that the data from the vector store was effectively used as context for the query.
Here are the steps that occur when the chain is executed:
- The model creates an embedding for the query.
- The query's embedding is used to locate data in the vector database that is similar to the query.
- Using the stuffing method, the final query is prepared, in which the original query is combined with the context returned from the vector database.
- The large language model answers the query, taking into account the provided context.
This process can be visualised as follows:
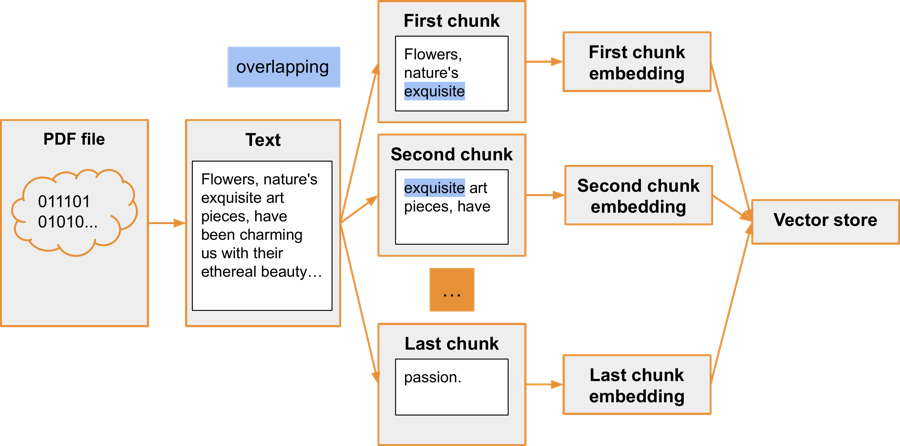
Loaders and splitters
LangChain offers the capability to load text from various sources, such as websites, PDF files, and more. This text often needs to be further segmented into smaller chunks that can be sent as context to a large language model.
Here's an example of loading a PDF file and dividing its text into chunks:
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
loader = PyPDFLoader("file.pdf")
text = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=30,
chunk_overlap=10,
)
documents = text_splitter.split_documents(text)
print(documents[0])
print(documents[1])
Output:
page_content="Flowers, nature's exquisite" metadata={'source': 'file.pdf', 'page': 0}
page_content='exquisite art pieces, have' metadata={'source': 'file.pdf', 'page': 0}
The output includes both the text content of a chunk and associated metadata. This metadata indicates the PDF file from which the text was loaded and the specific page within that PDF file where the text is located.
The original text of the PDF file is:
Flowers, nature's exquisite art pieces, have been charming us with their ethereal beauty and intoxicating fragrances since time immemorial. Each one is a unique spectacle, an intricate masterpiece delicately crafted by the hands of Mother Nature herself. Take the rose, for instance, a timeless symbol of love and passion.
First, the loader loads text from a PDF file. Then, the RecursiveCharacterTextSplitter divides the text into chunks of about 30 characters each, with an overlap of approximately 10 characters between chunks. This overlap is beneficial for maintaining the semantic meaning of a full sentence at the boundaries of the chunk. The given values for character splitting are artificially low in this example; in a production system, it would typically be a few thousand characters per chunk.
So, what's the next step with these chunks? Embeddings for them can be created and then stored in a vector store, such as FAISS or a similar system.
The entire process can be visualised as follows: