Chains
A chain acts as a unifying layer that encapsulates diverse components, which could include prompt templates, large language model wrappers, or even other chains. It efficiently links these components, facilitating their operation as a single entity. Each chain has designated input and output parameters, which aids in its linkage with other chains.
Additional features of a chain include:
- callbacks - these are activated during various stages of computation, such as at the commencement or conclusion of a chain's operation.
- memory - this feature allows the preservation of context variables across different runs of a chain.
LLMChain
The LLMChain combines a prompt template with a large language model wrapper. The prompt template, in conjunction with any potential input variables, is used as a prompt for the large language model. Subsequently, the output from the large language model is returned. Let's consider the example below:
from langchain import LLMChain, OpenAI, PromptTemplate
llm = OpenAI()
prompt_template = "Where do {animals} live?"
chain = LLMChain(llm=llm, prompt=PromptTemplate.from_template(prompt_template))
output = chain({"animals": "giraffes"})["text"]
print(output)
Output:
Giraffes live in the savannas of Africa.
Here's a diagram depicting the structure of the above LLMChain object:

A wrapper for the OpenAI LLM is combined with the prompt template Where do {animals} live? (by default, it uses the text-davinci-003 model). The input variables of this chain coincide with the input variables of the prompt template, in this case, animals. After substituting the formatted string with the parameter passed for the animals input variable, the full prompt provided to the large language model becomes Where do giraffes live?. The output variable, by default labeled as text, will hold the result produced by the large language model after it has processed the prompt.
There are several methods available for generating output using a chain.
from langchain import LLMChain, OpenAI, PromptTemplate
llm = OpenAI()
prompt_template = "Where do {animals} live?"
chain = LLMChain(llm=llm, prompt=PromptTemplate.from_template(prompt_template))
output = chain.run({"animals": "giraffes"})
print(output)
Output:
Giraffes live in the savannas of Africa, ranging from the west to east coasts of the continent.
The run method is akin to invoking the chain using the __call__ method. It produces a string as its outcome, which suggests that it is designed to support only one output.
from langchain import LLMChain, OpenAI, PromptTemplate
# the parameter n specifies how many generations to produce for a prompt
llm = OpenAI(n=2)
prompt_template = "Where do {animals} live?"
chain = LLMChain(llm=llm, prompt=PromptTemplate.from_template(prompt_template))
output = chain.generate([{"animals": "giraffes"}, {"animals": "kangaroos"}])
# two results for 'giraffes'
print(output.generations[0][0].text)
print(output.generations[0][1].text)
# two results for 'kangaroos'
print(output.generations[1][0].text)
print(output.generations[1][1].text)
Giraffes live in the savannas of Africa, where they roam among the open plains and woodlands.
Giraffes live in the savannas and open woodlands of sub-Saharan Africa.
Kangaroos are native to Australia and live in a variety of habitats, including grasslands, woodlands, and deserts.
Kangaroos are found in Australia and on nearby islands such as New Guinea and some of the smaller islands of Indonesia. They also live in the southern and eastern parts of New Zealand.
On the other hand, the generate method is capable of producing multiple outputs corresponding to multiple inputs.
Sequential chains
Sequential chains enable the combination of multiple chains into a single one. The output from each preceding chain is provided as input to the subsequent chain. There are two types of sequential chains: SimpleSequentialChain and SequentialChain.
SimpleSequentialChain
As the name suggests, SimpleSequentialChain is the simpler form of sequential chains. Each chain embedded within it can only have one input and one output.
Let's examine a SimpleSequentialChain:
from langchain import LLMChain, OpenAI, PromptTemplate
from langchain.chains import SimpleSequentialChain
llm = OpenAI(temperature=0)
animal_chain = LLMChain(
llm=llm, prompt=PromptTemplate.from_template("Where do {animals} live?")
)
translate_chain = LLMChain(
llm=llm, prompt=PromptTemplate.from_template("Translate to French: {sentence}")
)
chain = SimpleSequentialChain(chains=[animal_chain, translate_chain])
output = chain({"input": "giraffes"})["output"]
print(output)
Output:
Les girafes vivent dans les savanes et les forêts ouvertes d'Afrique.
This involves two chains:
- the first is a previously discussed chain that responds to queries about where specific animals live.
- the second chain translates the provided text into French.
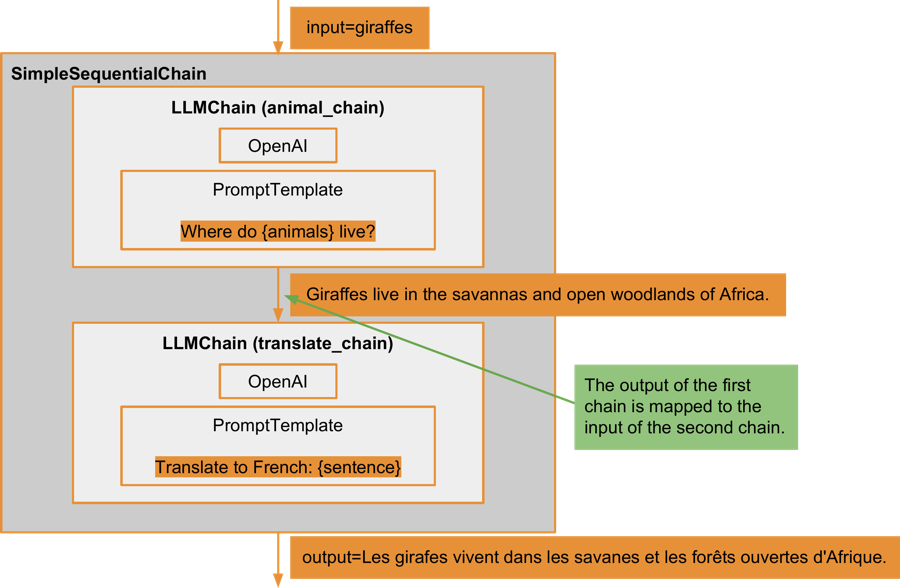
The input and output keys of the SimpleSequentialChain are simply named input and output. An animal name, in this case, a giraffe, is supplied as the sequential chain's input. This is then passed as the input to the first chain within the sequence, which responds to the query about where giraffes live. The output from this animal_chain might be something like Giraffes live in the savannas and open woodlands of Africa.. This sentence is then passed as the input to the second chain, translate_chain, which translates the text into French. The output of the translate_chain is the final output of the entire SimpleSequentialChain.
SequentialChain
The SequentialChain is designed to handle multiple inputs and generate multiple outputs, providing more flexibility than the SimpleSequentialChain.
from langchain import LLMChain, OpenAI, PromptTemplate
from langchain.chains import SequentialChain
llm = OpenAI(temperature=0)
animal_chain = LLMChain(
llm=llm,
prompt=PromptTemplate.from_template("Where do {animals} live?"),
output_key="sentence",
)
translate_chain = LLMChain(
llm=llm,
prompt=PromptTemplate.from_template("Translate to {language}: {sentence}"),
output_key="translated_sentence",
)
chain = SequentialChain(
input_variables=["animals", "language"],
output_variables=["sentence", "translated_sentence"],
chains=[animal_chain, translate_chain],
)
output = chain({"animals": "giraffes", "language": "German"})
print(output["sentence"])
print(output["translated_sentence"])
Output:
Giraffes live in the savannas and open woodlands of Africa.
Giraffen leben in den Savannen und offenen Wäldern Afrikas.
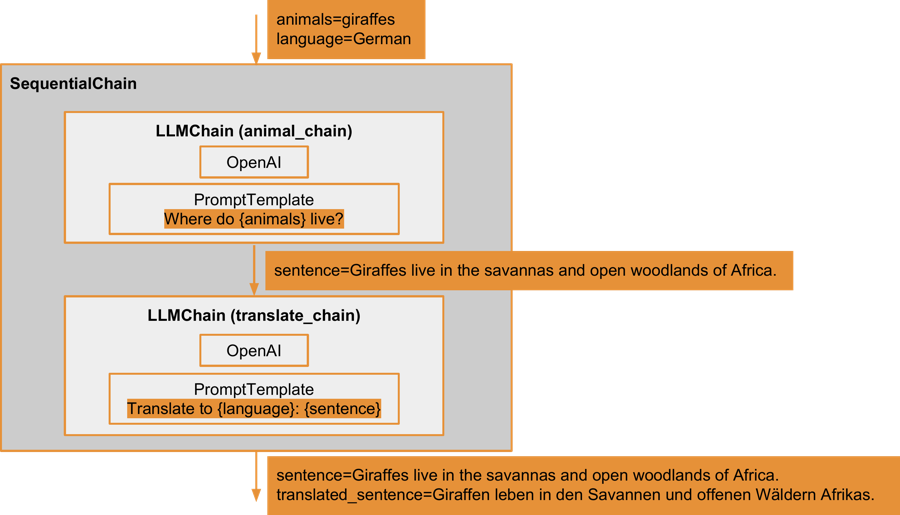
This sequential chain is designed to accommodate two input variables: animals for the first chain, and language to specify into which language the output from the first chain should be translated. The names of these input variables are determined during the creation of the sequential chain. The sequential chain also yields two outputs: the original English sentence generated by the large language model in response to the question about where giraffes live, and the translated sentence. The outputs from each LLMChain are specifically named to ensure accurate identification, as multiple outputs are permissible.
The visualisation of the described SequentialChain is as follows:
ConversationChain
The ConversationChain is a straightforward chain class derived from LLMChain. By default, it features a memory object that retains the dialog history with the large language model. This conversation history is transmitted as context for each new interaction with the large language model. Moreover, the chain's prompt directs the large language model to engage in conversation with the user. The prompt specifies two parties: the user as Human and the large language model as AI.
Let's examine an example involving two interactions with the large language model via ConversationChain:
from langchain.chains import ConversationChain
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI()
chain = ConversationChain(llm=llm)
print(chain("Where do giraffes live?"))
print(chain("What do they like to eat?"))
The large language model has been asked two questions.
The prompt for the initial interaction is:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: Where do giraffes live?
AI:
Output:
Giraffes are found in savannas, grasslands, and open woodlands in Africa. They can be found in around 15 African countries, including Kenya, Tanzania, and South Africa.
The prompt for the succeeding interaction incorporates the entire previous conversation extracted from the memory, along with the new question defined when invoking the chat model object:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: Where do giraffes live?
AI: Giraffes are found in savannas, grasslands, and open woodlands in Africa. They can be found in around 15 African countries, including Kenya, Tanzania, and South Africa.
Human: What do they like to eat?
AI:
Output:
Giraffes are herbivores and primarily eat leaves, flowers, and fruits from trees and shrubs. They are known to prefer certain species of trees, such as acacia, and have specialized tongues and necks that allow them to reach high into trees for their food.
It's worth noting that, based on the conversation history, the large language model accurately interpreted 'they' as referring to giraffes.
Callbacks
Callback functions serve as a flexible mechanism that can be integrated with various entities, including large language model wrappers, chains, or agents. They are designed to be invoked at distinct stages throughout an entity's lifecycle, including during initialisation, actual processing, de-initialisation, or when errors occur.
Let's illustrate this with an example showcasing the use of callback functions with a large language model wrapper:
from langchain import LLMChain, OpenAI, PromptTemplate
from langchain.callbacks.base import BaseCallbackHandler
class CustomCallbackHandler(BaseCallbackHandler):
def on_llm_start(self, serialized, prompts, invocation_params, **kwargs):
print(serialized["name"]) # OpenAI
print(prompts) # ['Where do giraffes live?']
print(invocation_params["model_name"]) # text-davinci-003
print(invocation_params["temperature"]) # 0.7
def on_llm_new_token(self, token: str, **kwargs) -> None:
print(repr(token))
def on_llm_end(self, response, **kwargs):
print(response.generations[0][0].text)
# Giraffes live in the savannas and grasslands of Africa.
llm = OpenAI(streaming=True)
prompt_template = "Where do {animals} live?"
chain = LLMChain(
llm=llm,
prompt=PromptTemplate.from_template(prompt_template),
)
output = chain.run({"animals": "giraffes"}, callbacks=[CustomCallbackHandler()])
print(output)
Generated tokens:
'\n'
'\n'
'G'
'ir'
'aff'
'es'
' live'
' in'
' the'
' sav'
'ann'
'as'
' and'
' open'
' wood'
'lands'
' of'
' sub'
'-'
'Saharan'
' Africa'
'.'
''
A class is defined that inherits from the BaseCallbackHandler base class, and several methods are overridden within this subclass:
on_llm_start: Triggered prior to dispatching a request to a large language model for output generation, this method retains information such as the name of the large language model wrapper, the prompts utilised, and the parameters configured for the large language model.on_llm_new_token: This method is applicable to large language models that support token streaming, meaning they return a newly generated token instantly instead of waiting for the entire response to be generated. This callback is activated each time a new token is returned and can be immediately utilised.on_llm_end: As the name suggests, this method is called once the large language model finishes generating output. It receives the produced output as a parameter.